Novos documentos de injeção imediata: Regra de dois dos agentes e o atacante se move em segundo lugar
2 de novembro de 2025
Dois novos artigos interessantes sobre segurança LLM e injeção imediata chamaram minha atenção neste fim de semana.
Regra de dois agentes: uma abordagem prática para segurança de agentes de IA
O primeiro é Regra de dois agentes: uma abordagem prática para segurança de agentes de IApublicado em 31 de outubro no blog Meta AI. Não lista os autores, mas foi compartilhado no Twitter pelo pesquisador de segurança da Meta AI, Mick Ayzenberg.
Ele propõe uma “Regra de Dois” inspirada tanto no meu próprio conceito de trifecta letal quanto no da equipe do Google Chrome. Regra de 2 para escrever código que funcione com entradas não confiáveis:
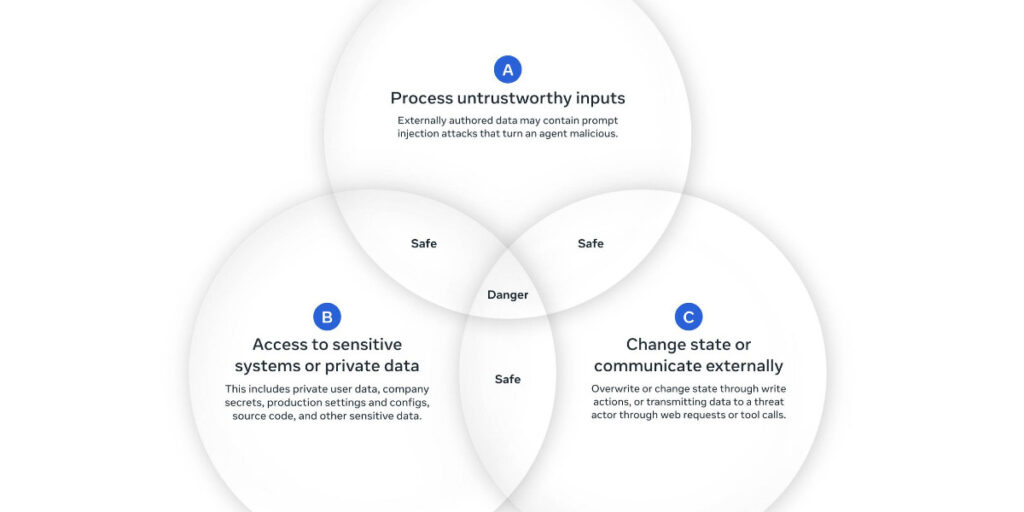
Em alto nível, a Regra de Dois Agentes afirma que até que a pesquisa de robustez nos permita detectar e recusar com segurança a injeção imediata, os agentes não deve satisfazer mais do que dois das três propriedades a seguir em uma sessão para evitar as consequências de maior impacto da injeção imediata.
(UM) Um agente pode processar entradas não confiáveis
(B) Um agente pode ter acesso a sistemas confidenciais ou dados privados
(C) Um agente pode mudar de estado ou se comunicar externamente
Ainda é possível que todas as três propriedades sejam necessárias para realizar uma solicitação. Se um agente exigir todos os três sem iniciar uma nova sessão (ou seja, com uma nova janela de contexto), então o agente não deverá ter permissão para operar de forma autônoma e, no mínimo, exigir supervisão — por meio de aprovação humana ou outro meio confiável de validação.
É acompanhado por este diagrama útil:
eu gosto deste bastante.
Passei vários anos tentando encontrar maneiras claras de explicar os riscos de ataques de injeção imediata para desenvolvedores que estão construindo com base em LLMs. É frustrantemente difícil.
Tive mais sucesso com a trifeta letal, que resume uma classe específica de ataque de injeção imediata em um modelo bastante simples: se o seu sistema tiver acesso a dados privados, exposição a conteúdo não confiável e uma maneira de se comunicar externamente, ele estará vulnerável ao roubo de dados privados.
O único problema com a trifeta letal é que ela cobre apenas o risco de exfiltração de dados: há muitos outros riscos, ainda mais desagradáveis, que surgem de ataques de injeção imediata contra agentes alimentados por LLM com acesso a ferramentas que a trifeta letal não cobre.
A Regra de Dois dos Agentes resolve isso perfeitamente, adicionando a “mudança de estado” como uma propriedade a ser considerada. Isso traz outras formas de uso de ferramentas: qualquer coisa que possa mudar de estado acionada por entradas não confiáveis é algo com que devemos ter muito cuidado.
Também é revigorante ver outro grande laboratório de pesquisa concluindo que a injeção imediata continua sendo um problema não resolvido e que as tentativas de bloqueá-las ou filtrá-las não se mostraram confiáveis o suficiente para serem confiáveis. A solução atual é projetar sistemas com isso em mente, e a Regra de Dois é uma forma sólida de pensar sobre isso.
O que me leva ao segundo artigo…
O atacante se move em segundo lugar: ataques adaptativos mais fortes contornam as defesas contra jailbreaks LLM e injeções imediatas
Este artigo é datado de 10 de outubro de 2025 no Arxiv e vem de uma equipe de 14 autores – Milad Nasr, Nicholas Carlini, Chawin Sitawarin, Sander V. Schulhoff, Jamie Hayes, Michael Ilie, Juliette Pluto, Shuang Song, Harsh Chaudhari, Ilia Shumailov, Abhradeep Thakurta, Kai Yuanqing Xiao, Andreas Terzis, Florian Tramèr – incluindo representantes da OpenAI, Anthropic e Google DeepMind.
O artigo analisa 12 defesas publicadas contra injeção imediata e jailbreak e as submete a uma série de “ataques adaptativos” – ataques que podem despender um esforço considerável iterando várias vezes para tentar encontrar uma saída.
As defesas não se saíram bem:
Ao ajustar e dimensionar sistematicamente técnicas gerais de otimização – gradiente descendente, aprendizado por reforço, busca aleatória e exploração guiada por humanos – contornamos 12 defesas recentes (baseadas em um conjunto diversificado de técnicas) com taxa de sucesso de ataque acima de 90% para a maioria; Mais importante ainda, a maioria das defesas relatou originalmente taxas de sucesso de ataque próximas de zero.
Notavelmente, o “ambiente de equipe vermelha humana” marcou 100%, derrotando todas as defesas. Essa equipe vermelha consistia em 500 participantes em uma competição online que eles realizaram com um prêmio de US$ 20 mil.
O ponto principal do artigo é que exemplos de ataques estáticos – prompts de sequência única projetados para contornar sistemas – são uma forma quase inútil de avaliar essas defesas. Os ataques adaptativos são muito mais poderosos, conforme mostrado neste gráfico:
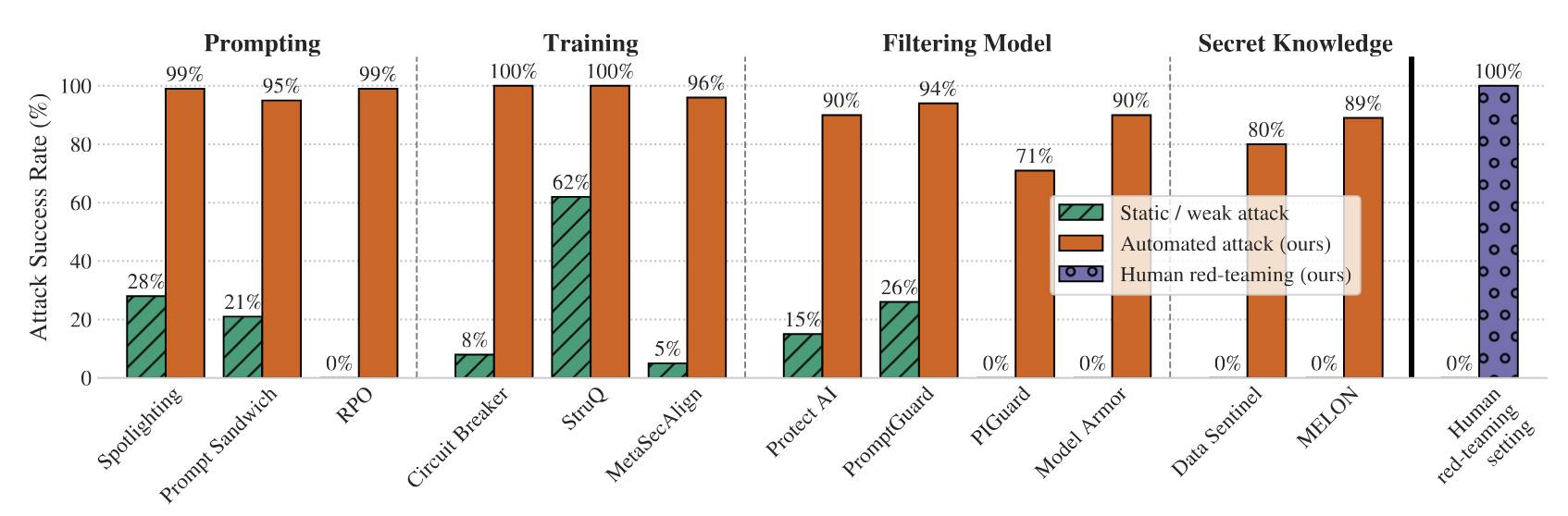
As três técnicas de ataque adaptativo automatizado usadas pelo artigo são:
- Métodos baseados em gradiente—estes foram os menos eficazes, usando a técnica descrita no lendário Ataques adversários universais e transferíveis em modelos de linguagem alinhada artigo de 2023.
- Métodos de aprendizagem por reforço—particularmente eficaz contra modelos caixa-preta: “permitimos que o modelo atacante interagisse diretamente com o sistema defendido e observasse seus resultados”, utilizando 32 sessões de 5 rodadas cada.
- Métodos baseados em pesquisa—gerar candidatos com um LLM, depois avaliá-los e modificá-los usando LLM como juiz e outros classificadores.
O artigo conclui de forma um tanto otimista:
(…) Avaliações adaptativas são, portanto, mais desafiadoras de realizar, tornando ainda mais importante que sejam realizadas. Mais uma vez instamos os autores de defesa a lançarem defesas simples, fáceis de solicitar e que sejam passíveis de análise humana. (…) Finalmente, esperamos que a nossa análise aqui aumente o padrão para avaliações de defesa e, ao fazê-lo, aumente a probabilidade de desenvolvimento de defesas confiáveis de jailbreak e de injeção imediata.
Dada a forma como as defesas foram totalmente derrotadas, não partilho o seu optimismo de que defesas fiáveis serão desenvolvidas tão cedo.
Como uma revisão do quão longe ainda temos que ir, este artigo tem um impacto poderoso. Acho que é um forte argumento para a Regra de Dois Agentes da Meta como o melhor conselho prático para a construção de sistemas de agentes seguros baseados em LLM hoje, na ausência de defesas de injeção imediata nas quais possamos confiar.
Café Codificado é um portal dinâmico e confiável criado especialmente para desenvolvedores. Nosso foco é entregar:
Dicas práticas para programação, produtividade, frameworks, testes, DevOps e muito mais;
Notícias atualizadas, acompanhando tendências e lançamentos do mundo da tecnologia, compiladas com relevância e sem jargões desnecessários.
O que você encontra aqui:
Artigos objetivos e comandáveis — Tutoriais, tutoriais passo-a-passo e dicas que vão direto ao ponto.
Cobertura das tecnologias que estão em alta — do universo da IA, computação em nuvem e segurança à engenharia de software e criatividade em código.
Conteúdo para todos os níveis — de iniciantes buscando praticidade, a profissionais em busca de insights estratégicos e aperfeiçoamento.
Comunidade ativa — textos humanizados, perguntinhas instigantes e espaço para você contribuir com reflexões e comentários.