Codifique projetos de pesquisa com agentes de codificação assíncrona como Claude Code e Codex
6 de novembro de 2025
Tenho experimentado recentemente um padrão de uso de LLM que está funcionando muito bem: tarefas de pesquisa de código assíncrono. Escolha uma questão de pesquisa, crie um agente de codificação assíncrona e deixe-o ir, execute alguns experimentos e relate quando terminar.
Pesquisa de código
O desenvolvimento de software se beneficia enormemente de algo que chamo pesquisa de código. A grande vantagem das perguntas sobre código é que muitas vezes elas podem ser respondidas de forma definitiva escrevendo e executando código.
Muitas vezes vejo perguntas em fóruns que sugerem falta de compreensão dessa habilidade.
“O Redis poderia funcionar para alimentar o feed de notificações do meu aplicativo?” é um ótimo exemplo. A resposta é sempre “depende”, mas uma resposta melhor é que um bom programador já tem tudo o que precisa para responder a essa pergunta por si mesmo. Crie uma prova de conceito, simule os padrões que você espera ver na produção e, em seguida, execute experimentos para ver se funcionará.
Há muito tempo que sou um praticante entusiasta da pesquisa de código. Muitos dos meus projetos mais interessantes começaram como algumas dezenas de linhas de código experimental para provar a mim mesmo que algo era possível.
Agentes de codificação
Acontece agentes de codificação como Claude Code e Codex também são uma opção fantástica para esse tipo de trabalho. Dê-lhes o objetivo certo e um ambiente útil e eles concluirão um projeto de pesquisa básica sem qualquer supervisão adicional.
LLMs alucinam e cometem erros. Isso é muito menos importante para tarefas de pesquisa de código porque o código em si não mente: se eles escrevem o código e o executam e ele faz as coisas certas, então eles demonstraram para si mesmos e para você que algo realmente funciona.
Eles não podem provar que algo é impossível – só porque o agente de codificação não conseguiu encontrar uma maneira de fazer algo não significa que não possa ser feito – mas muitas vezes podem demonstrar que algo é possível em apenas alguns minutos de trituração.
Agentes de codificação assíncrona
Usei agentes de codificação interativos como Claude Code e Codex CLI para vários deles, mas hoje estou recorrendo cada vez mais aos seus agente de codificação assíncrona em vez disso, membros da família.
Um agente de codificação assíncrona é um agente de codificação que opera do tipo “dispare e esqueça”. Você impõe uma tarefa, ele é executado em um servidor em algum lugar e, quando termina, ele envia uma solicitação pull no repositório GitHub escolhido.
OpenAI’s Nuvem CodexAntrópico Código Claude para webGoogle Gêmeos Júlioe GitHub Agente de codificação copiloto são quatro exemplos proeminentes desse padrão.
Estes são fantástico ferramentas para projetos de pesquisa de código. Estabeleça um objetivo claro, transforme-o em alguns parágrafos de instruções, solte-os e volte dez minutos depois para ver o que eles descobriram.
Estou iniciando de 2 a 3 projetos de pesquisa de código por dia agora. Meu comprometimento de tempo é mínimo e eles frequentemente retornam com resultados úteis ou interessantes.
Dê a eles um repositório GitHub dedicado
Você pode executar uma tarefa de pesquisa de código em um repositório GitHub existente, mas acho muito mais libertador ter um repositório separado e dedicado para seus agentes de codificação executarem seus projetos.
Isso libera você de ficar limitado a pesquisar apenas o código que você já escreveu e também significa que você pode ser muito menos cauteloso sobre o que permite que os agentes façam.
Eu tenho dois repositórios que uso para isso – um público e um privado. Utilizo o público para tarefas de pesquisa que não precisam ser privadas, e o privado para qualquer coisa que ainda não esteja pronto para compartilhar com o mundo.
Deixe-os explorar com acesso ilimitado à rede
O maior benefício de um repositório dedicado é que você não precisa ser cauteloso sobre o que os agentes que operam nesse repositório podem fazer.
Tanto o Codex Cloud quanto o Claude Code para web executam agentes em um ambiente bloqueado, com restrições estritas sobre como eles podem acessar a rede. Isso faz todo o sentido se eles estiverem sendo executados em repositórios confidenciais – um ataque de injeção imediata da variedade letal trifecta poderia facilmente ser usado para roubar código confidencial ou variáveis de ambiente.
Se você estiver executando em um repositório novo e não confidencial, não precisa se preocupar com isso! Configurei meus repositórios de pesquisa para acesso total à rede, o que significa que meus agentes de codificação podem instalar quaisquer dependências que precisarem, buscar dados da web e geralmente fazer qualquer coisa que eu possa fazer em meu próprio computador.
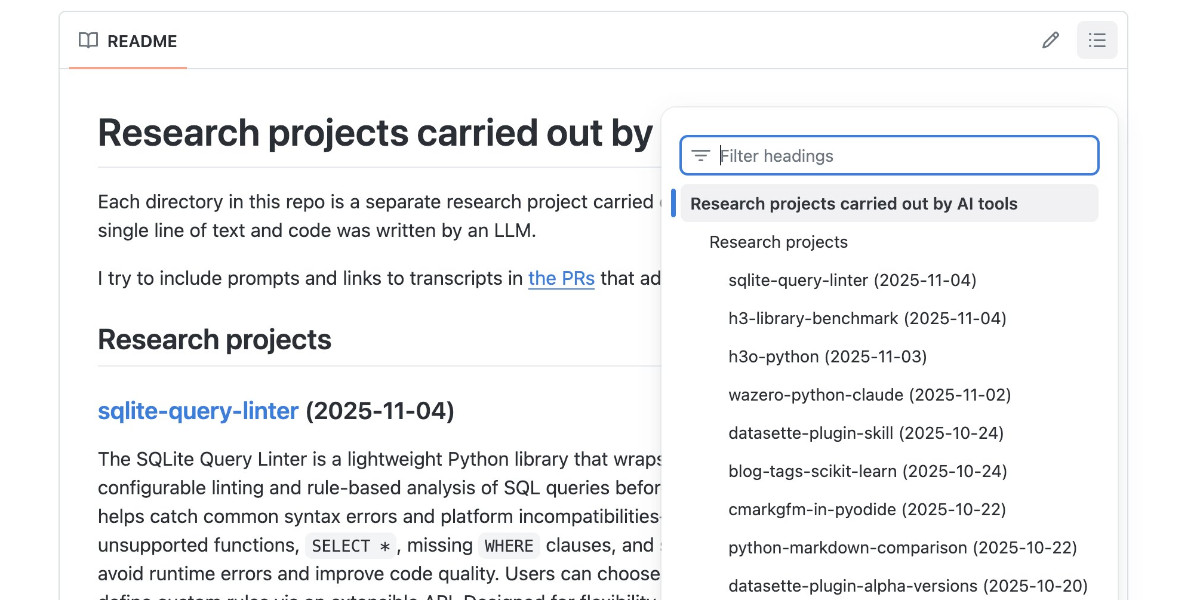
Minha coleção simonw/pesquisa
Vamos mergulhar em alguns exemplos. Meu repositório público de pesquisa está em simonw/pesquisa no GitHub. Atualmente contém 13 pastas, cada uma das quais é um projeto de pesquisa separado. Eu o criei há apenas duas semanas, então já estou fazendo uma média de quase um por dia!
Também inclui um fluxo de trabalho GitHub que usa Modelos GitHub para atualizar automaticamente o LEIA-ME arquivo com um resumo de cada novo projeto, usando Engrenagem, LLM, modelos llm-github e este trecho de Python.
Aqui estão alguns exemplos de projetos de pesquisa do repositório.
nó-piodeto mostra um exemplo de Script Node.js. que executa o Piodídeo Distribuição WebAssembly de Python dentro dele – mais uma de minhas tentativas contínuas de encontrar uma ótima maneira de executar Python em uma sandbox WebAssembly em um servidor.
comparação de marcação python (transcrição) fornece um benchmark de desempenho detalhado de sete bibliotecas Python Markdown diferentes. Eu disparei este porque tropecei cmmarkgfmuma ligação Python em torno da implementação Markdown do GitHub em C, e queria ver como ela se comparava às outras opções. Este produziu alguns gráficos! cmarkgfm saiu vencedor por uma margem significativa:
Aqui está todo o prompt que usei para esse projeto:
Crie um benchmark de desempenho e um relatório de comparação de recursos no PyPI cmarkgfm em comparação com outras bibliotecas populares de markdown do Python – verifique todos eles no github e leia a fonte para ter uma ideia dos recursos, em seguida, projete e execute um benchmark incluindo a geração de alguns gráficos e, em seguida, crie um relatório em uma nova pasta python-markdown-comparison (não crie um arquivo _summary.md ou edite em qualquer lugar fora dessa pasta). Certifique-se de que as imagens do gráfico de desempenho sejam exibidas diretamente no README.md da pasta.
Observe que não especifiquei nenhuma biblioteca Markdown além de cmarkgfm—Claude Code fez uma busca e encontrou os outros seis sozinho.
cmarkgfm-em-piodeto é muito mais divertido. Uma coisa interessante sobre ter todos os meus projetos de pesquisa no mesmo repositório é que novos projetos podem ser baseados em projetos anteriores. Aqui eu decidi ver o quão difícil seria conseguir cmarkgfm—que tem uma extensão C—trabalhando dentro do Pyodide dentro do Node.js. Claude compilou com sucesso um arquivo de 88,4 KB cmarkgfm_pyodide-2025.10.22-cp312-cp312-emscripten_3_1_46_wasm32.whl arquivo com a extensão C necessária e provou que poderia ser carregado no Pyodide no WebAssembly dentro do Node.js.
Executei este usando Claude Code em meu laptop depois que uma tentativa inicial falhou. O prompt inicial foi:
Descubra como obter o amante de descontos cmarkgfm (erro de digitação no prompt, deveria ser “biblioteca”, mas descobri mesmo assim) para Python trabalhando em pyodide. Isso será difícil porque ele usa C, então você precisará compilá-lo para webassembly compatível com pyodide de alguma forma. Escreva um relatório sobre seus resultados e código para um novo diretório cmarkgfm-in-pyodide. Teste-o usando pytest para exercitar um script de teste node.js que chama pyodide conforme visto nos diretórios node.js e pyodide existentes
Existe uma filial que foi uma tentativa inicial desta pesquisa, mas que falhou por não ter acesso à Internet. Você tem acesso à Internet. Use essa ramificação existente para acelerar seu trabalho, mas não comprometa nenhum código, a menos que tenha certeza de ter executado com sucesso testes que comprovem que o módulo pyodide que você criou funciona corretamente.
Este desistiu no meio do caminho, reclamando que o emscripten demoraria muito. Eu disse:
Conclua este projeto, execute o emscripten, não me importa quanto tempo demore, atualize o relatório se funcionar
Ele demorou um pouco mais e reclamou que a biblioteca Python existente usava CFFI, que não está disponível no Pyodide. Eu perguntei:
Você consegue descobrir como reescrever o cmarkgfm para não usar FFI e, em vez disso, usar uma maneira amigável de integrar esse código C?
… e aconteceu. Você pode veja a transcrição completa aqui.
blog-tags-scikit-learn. Fazendo uma pequena pausa no WebAssembly, pensei que seria divertido colocar scikit-aprender através de uma tarefa de classificação de texto em meu blog:
Trabalhe em uma nova pasta chamada blog-tags-scikit-learn
Download
https://datasette.simonwillison.net/simonwillisonblog.db—um banco de dados SQLite. Dê uma olhada na tabela blog_entry e nas tags associadas – muitas das entradas anteriores não têm tags associadas a elas, enquanto as entradas posteriores têm. Projetar, implementar e executar modelos para sugerir tags para as entradas anteriores com base na análise textual das posterioresUse Python scikit learn e experimente várias estratégias diferentes
Produza JSON dos resultados para cada um, além de scripts para executá-los e uma descrição detalhada do markdown
Inclua também uma página HTML com uma boa visualização dos resultados que funciona carregando esses arquivos JSON.
Isso resultou em sete .py arquivos, quatro .json arquivos de resultados e um detalhado relatório. (Ele ignorou a parte sobre uma página HTML com uma bela visualização por algum motivo.) Nada mal para alguns momentos de curiosidade ociosa digitados em meu telefone!
São apenas três dos treze projetos no repositório até agora. O histórico de commits de cada um geralmente está vinculado ao prompt e, às vezes, à transcrição, se você quiser ver como eles se desenrolaram.
Mais recentemente adicionei um breve AGENTS.md arquivo para o repositório com algumas dicas extras para meus agentes de pesquisa. Você pode leia isso aqui.
Isso é um desleixo total, claro
Minha definição preferida de desperdício de IA é conteúdo gerado por IA que é publicado sem revisão humana. Eu mesmo não revisei esses relatórios detalhadamente e normalmente não os publicaria on-line sem algumas edições e verificações sérias.
Quero compartilhar o padrão que estou usando, então decidi mantê-los em quarentena neste público simonw/research repositório.
Uma pequena solicitação de recurso para GitHub: eu adoraria poder marcar um repositório como “excluir dos índices de pesquisa”, de forma que ele seja rotulado com etiquetas. Ainda gosto de manter o conteúdo gerado por IA fora da pesquisa, para evitar contribuir mais para o internet morta.
Experimente você mesmo
É muito fácil começar a experimentar esse padrão de pesquisa de agente de codificação. Crie um repositório GitHub gratuito (público ou privado) e deixe alguns agentes soltos nele e veja o que acontece.
Você pode executar agentes localmente, mas acho os agentes assíncronos mais convenientes, especialmente porque posso executá-los (ou acioná-los no meu telefone) sem medo de que danifiquem minha própria máquina ou vazem qualquer um dos meus dados privados.
Código Claude para ofertas da web $ 250 grátis em créditos para usuários de US$ 20/mês por tempo limitado (até 18 de novembro de 2025). Gêmeos Jules tem um nível gratuito. Existem muitos outros agentes de codificação que você também pode experimentar.
Deixe-me saber se seus agentes de pesquisa voltarem com algo interessante!
Café Codificado é um portal dinâmico e confiável criado especialmente para desenvolvedores. Nosso foco é entregar:
Dicas práticas para programação, produtividade, frameworks, testes, DevOps e muito mais;
Notícias atualizadas, acompanhando tendências e lançamentos do mundo da tecnologia, compiladas com relevância e sem jargões desnecessários.
O que você encontra aqui:
Artigos objetivos e comandáveis — Tutoriais, tutoriais passo-a-passo e dicas que vão direto ao ponto.
Cobertura das tecnologias que estão em alta — do universo da IA, computação em nuvem e segurança à engenharia de software e criatividade em código.
Conteúdo para todos os níveis — de iniciantes buscando praticidade, a profissionais em busca de insights estratégicos e aperfeiçoamento.
Comunidade ativa — textos humanizados, perguntinhas instigantes e espaço para você contribuir com reflexões e comentários.